CS4215 Project Report
Title: Explicit-control evaluator (ECE) for Go
Team Members: Rama Aryasuta Pangestu (A0236444E), Yeung Man Tsung (A0255829N)
Repository URL: https://github.com/benson1029/go-slang
Live Demo: https://benson1029.github.io/go-slang/
Presentation Slides: CS4215_Presentation_Slides.pdf
This report can be viewed online on https://benson1029.github.io/go-slang/docs/project-report/report.
Table of Contents
Project Objectives
We implement an explicit-control evaluator (ECE) for the following subset of the Go programming language:
- Sequential constructs: Variable declarations and assignments, expressions, control flow (
if, for), functions, and complex types (strings, structs, arrays, slices).
- Concurrent constructs: Goroutines, mutex, wait groups, channels, and
select statements.
Additionally, we implement a low-level memory management system with both reference counting and mark-and-sweep garbage collection. All data structures, including control stack, heap, and environments, are stored in a single array buffer. We also implement a visualizer for the ECE machine.
All objectives are met in the final implementation. However, the following language features are not in scope:
- Sequential constructs:
switch statements, defer statements, and panic and recover functions. Anonymous structs, indexing and slicing of strings, pointers, maps and tuples are also not implemented.
- Concurrent constructs: Closing of channels is not implemented.
The exact subset of the Go programming language that we support, along with some examples, can be found in the language specification page.
Language Processing Steps
Externally, this ECE machine is an interpreter for Go written in JavaScript, which is then run in a JavaScript interpreter (the browser). This is shown using the following T-diagram:
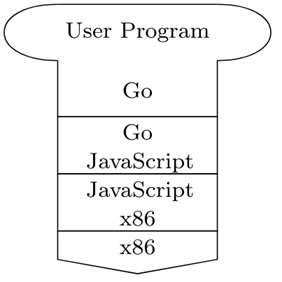
Internally, the Go program is first parsed into an abstract syntax tree (AST) using a parser, generated with peg.js using our own syntax definition. The AST is then preprocessed by a preprocessor, which annotates the global scope declarations with their necessary captures and then sorts the global scope declarations such that their dependencies are satisified. The preprocessed AST is then passed to a loader, which loads the entire program into the heap and initializing the Control stack in the ECE machine. The ECE machine then executes the instructions in the Control stack.
ECE Specification
Instruction Set
The following tables show the instruction set of the ECE machine.
Helper Instructions
| Instruction | Description | Parameters | Stash |
|---|
PUSH_I | Pushes a value into the stash | value (value) | None |
POP_I | Pops a value from the stash | None | value (value) |
Expressions
| Instruction | Description | Parameters | Stash |
|---|
BINARY | Performs a binary operation (includes logical operations) | operator (string), left_operand (rvalue expression), right_operand (rvalue expression) | None |
BINARY_I | Performs a binary operation | operator (string) | None |
LOGICAL_IMM_I | Performs a logical operation with only the left operand in the stash | operator (string), right_operand (rvalue expression) | left_operand (value) |
LOGICAL_I | Performs a logical operation with only the right operand in the stash | operator (string) | right_operand (value) |
UNARY | Performs a unary operation | operator (string), operand (rvalue expression) | None |
UNARY_I | Performs a unary operation | operator (string) | None |
LITERAL | Pushes a literal value into the stash | type (string), value (value) | None |
Variables
| Instruction | Description | Parameters | Stash |
|---|
ASSIGN | Assigns a value to a variable | name (lvalue expression), value (rvalue expression) | None |
ASSIGN_I | Assigns a value to a variable | None | name (address), value (value) |
VAR | Declares a variable with an initial value | name (string), value (rvalue expression) | None |
VAR_I | Declares a variable with an initial value | name (string) | value (value) |
NAME | Accesses the value of a variable | name (string) | None |
NAME_ADDRESS | Accesses the address of a variable | name (string) | None |
Control Flow
| Instruction | Description | Parameters | Stash |
|---|
SEQUENCE | Executes a sequence of instructions | body (linked list of instructions) | None |
BLOCK | Starts a scope, i.e. pushes a new environment frame | body (sequence) | None |
EXIT_SCOPE_I | Exits the current scope, i.e. pops the environment frame | None | None |
IF | Conditional statement | condition (rvalue expression), then_body (block), else_body (block) | None |
IF_I | Conditional statement | then_body (block), else_body (block) | condition (boolean) |
FOR | Iterative statement | init (statement), condition (rvalue expression), update (statement), body (block) | None |
FOR_I | Iterative statement | condition (rvalue expression), update (statement), body (block), loopVar (name or null) | condition (boolean) |
MARKER_I | Marker to signify the end of the loop body | None | None |
BREAK | Breaks out of the loop | None | None |
CONTINUE | Continues to the next iteration of the loop | None | None |
Functions
| Instruction | Description | Parameters | Stash |
|---|
FUNCTION | Declares a function | name (string), param_names (array of strings), capture_names (array of strings), body (block) | None |
CALL | Calls a function | function (rvalue expression), args (array of rvalue expressions) | None |
CALL_I | Calls a function | num_args (int) | function (value), args (array of values) |
CALL_STMT | Calls a function and discards the return value | body (a CALL instruction) | None |
RETURN | Returns a value from a function | value (rvalue expression) | None |
RETURN_I | Returns a value from a function | None | value (value) |
RESTORE_ENV_I | Restores the environment frame before the function call | frame (environment frame) | None |
Constructors
| Instruction | Description | Parameters | Stash |
|---|
DEFAULT_MAKE | Pushes the default value of a type into the stash | type (string), args (array of any) | None |
MAKE | Constructs a value of a type according to the make function call | type (string), args (array of rvalue expressions) | None |
MAKE_I | Constructs a value of a type according to the make function call | type (string), num_args (int) | args (array of values) |
CONSTRUCTOR | Constructs a value of a type according to the initializer list {...} | type (string), args (array of rvalue expressions) | None |
CONSTRUCTOR_I | Constructs a value of a type according to the initializer list {...} | type (string), num_args (int) | args (array of values) |
Arrays
| Instruction | Description | Parameters | Stash |
|---|
INDEX | Accesses the value of an array element | array (rvalue expression), index (rvalue expression) | None |
INDEX_I | Accesses the value of an array element | None | array (value), index (value) |
INDEX_ADDRESS | Accesses the address of an array element | array (rvalue expression), index (rvalue expression) | None |
INDEX_ADDRESS_I | Accesses the address of an array element | None | array (address), index (value) |
Structs
| Instruction | Description | Parameters | Stash |
|---|
STRUCT | Declares a struct | name (string), fields (array of names and types) | None |
METHOD | Declares a method for a struct | struct_name (string, name of the struct), name (string), self_name (string), param_names (array of strings), capture_names (array of strings), body (block) | None |
MEMBER | Accesses the value of a struct member | object (rvalue expression), member (string) | None |
MEMBER_I | Accesses the value of a struct member | None | object (value), member (string) |
MEMBER_ADDRESS | Accesses the address of a struct member | object (rvalue expression), member (string) | None |
MEMBER_ADDRESS_I | Accesses the address of a struct member | None | object (address), member (string) |
METHOD_MEMBER | Accesses the value of a method member, and pushes the current object into the stash (for the method call to use) | object (rvalue expression), member (string) , struct (string, name of the struct, annotated during type checking) | None |
Slices
| Instruction | Description | Parameters | Stash |
|---|
SLICE | Slices an array | array (rvalue expression), start (rvalue expression), end (rvalue expression) | None |
SLICE_I | Slices an array | None | array (value), start (value), end (value) |
SLICE_ADDRESS | Slices an array | array (rvalue expression), start (rvalue expression), end (rvalue expression) | None |
SLICE_ADDRESS_I | Slices an array | None | array (address), start (value), end (value) |
Goroutines and Channels
| Instruction | Description | Parameters | Stash |
|---|
GO_CALL_STMT | Calls a function in a new goroutine | body (a CALL instruction) | None |
GO_CALL_I | Calls a function in a new goroutine | num_args (int) | function (value), args (array of values) |
CHAN_RECEIVE | Receives a value from a channel | channel (rvalue expression) | None |
CHAN_RECEIVE_I | Receives a value from a channel | None | channel (address) |
CHAN_RECEIVE_STMT | Receives a value from a channel and discards it | body (a CHAN_RECEIVE instruction) | None |
CHAN_SEND | Sends a value to a channel | channel (rvalue expression), value (rvalue expression) | None |
CHAN_SEND_I | Sends a value to a channel | None | channel (address), value (value) |
SELECT | Selects a case from a list of cases | cases (array of cases) | None |
SELECT_I | Selects a case from a list of cases, with the expressions already evaluated | select (a SELECT instruction) | The evaluated expressions for all cases |
CASE_SEND | A case for sending to a channel | channel (rvalue expression), value (rvalue expression), body (sequence) | None |
CASE_RECEIVE | A case for receiving from a channel | channel (rvalue expression), assign (null or lvalue expression), body (sequence) | None |
CASE_DEFAULT | A default case | body (sequence) | None |
State Representation
⋅∥⋅ denotes the concatenation of two elements. For example, x∥y is the concatenation of x and y. In particular, x∥∅=x, ∅∥y=y, and ∅∥∅=∅.
The ECE machine has the scheduler T=Ti1∥Ti2∥…, where Ti1,Ti2,… are the (unblocked) threads in the scheduler. Each thread Ti is a tuple (C,S,E), where C is the control stack (containing instructions), S is the stash (containing runtime values for instructions), and E is the environment.
The control stack and the stash are represented as the concatenation of its elements x1∥x2∥x3∥…∥xk. The environment is a tuple E=(ΔN,ΔS), where ΔN and ΔS are the name and struct frames, respectively.
- ΔN is a concatenation of environment frames Δ1∥Δ2∥…∥Δn, where each environment frame Δi is a hash table that maps variable names to its address in the heap.
- ΔS is a hash table that maps struct names and methods to their addresses in the heap. Currently, we only support struct declarations on the global scope, so there is a single struct frame ΔS for the entire program.
A variable x is a pointer to a value v in the heap (the value for the variable). Therefore, a variable will have a fixed address a in the heap. When a variable is inserted into an environment frame, the environment frame hash table keeps a mapping from the variable name (represented by a string object in the heap) to its fixed address a in the heap.
We define the following operations on the environment:
- ∅∥Δ is the environment frame Δ with a new empty child frame.
- Δ[x←v] is the environment frame Δ with the variable x bound to the value v.
- Δ(x) is the value bound to the variable x in the environment frame Δ.
- Δ(x)a is the address of the variable x in the environment frame Δ.
If we update the value of an object in address a to a new value v, this change is reflected in all threads that have a reference to the address a. As this is a global change, we denote this operation as H[a←v], where H is the heap. Similarly, we can denote H(a) as the value at address a in the heap.
However, it's not just the values of environment variables which are stored in the heap. The scheduler T, each of its threads Ti=(Ci,Si,Ei), the control stack Ci, the stash Si, and the environment Ei=(ΔNi,ΔSi) are all stored in the heap. We denote the address Ta of the scheduler in the heap such that H(Ta)=T.
Therefore, since all objects determining the state of the ECE machine are stored in the heap, we have the following state representation:
The state of the ECE machine is the heap H.
For clarity, however, we will slightly abuse notation and denote the state of the ECE machine as (T,H), where T=H(Ta). It is important to remember that this is a shorthand notation to easily refer to the scheduler T, and the actual state of the ECE machine only depends on the heap H.
This shorthand notation allows us to treat T as if it's a separate entity from the heap H, but note that any changes to T are also reflected in H. In other words, we can view T in (T,H) as a (mutable) reference to the scheduler object H(Ta) in the heap H. Implicitly, we treat the children of the scheduler T (i.e. the threads Ti and their control stacks Ci, stashes Si, and environments Ei=(ΔNi,ΔSi)) as mutable references to their respective objects in the heap H as well.
We define the transition function ⇉T,H that maps the current state (T,H) to the next state (T′,H′) after evaluation, i.e. (T,H)⇉T,H(T′,H′).
To avoid clutter, most of the time we will only show the scheduler T in the inference rules, and only mention the heap H when we modify an existing object in the heap directly other than the scheduler and its children. As a shorthand, we define the transition function ⇉T that maps the current state (T,H) to the next state (T′,H[Ta←T′]) after evaluation, i.e. T⇉TT′.
Inference Rules for Selected Parts
We define inference rules for selected instructions of our ECE machine.
Helper Instructions
PUSH_I and POP_I have the following inference rules:
(PUSH_I v∥C,S,E)∥T⇉TT∥(C,v∥S,E)
(POP_I∥C,v∥S,E)∥T⇉TT∥(C,S,E)
Expressions
Literals, unary operators, and binary operators are evaluated using the LITERAL, UNARY, and BINARY instructions. However, for binary logical operators, we have short-circuit evaluation. The LOGICAL_IMM_I instruction evaluates the left operand first, and if the result is sufficient to determine the result of the logical operation, it will not evaluate the right operand.
This is shown in the following inference rules:
I=(BINARY operator EL ER)(operator=&&∨operator=||)(I ∥C,S,E)∥T⇉TT∥(EL∥LOGICAL_IMM_I operator ER∥C,S,E)
I=(LOGICAL_IMM_I && ER)(I ∥C,false∥S,E)∥T⇉TT∥(C,false∥S,E)
I=(LOGICAL_IMM_I && ER)(I ∥C,true∥S,E)∥T⇉TT∥(ER∥LOGICAL_I &&∥C,S,E)
I=(LOGICAL_IMM_I || ER)(I ∥C,true∥S,E)∥T⇉TT∥(C,true∥S,E)
I=(LOGICAL_IMM_I || ER)(I ∥C,false∥S,E)∥T⇉TT∥(ER∥LOGICAL_I ||∥C,S,E)
I=(LOGICAL_I operator)(I ∥C,false∥S,E)∥T⇉TT∥(C,false∥S,E)
I=(LOGICAL_I operator)(I ∥C,true∥S,E)∥T⇉TT∥(C,true∥S,E)
Variables
We can declare a variable with an initial value using the VAR instruction. The VAR instruction will push the initial value into the stash, followed by the VAR_I instruction to create a new variable in the environment frame.
This is shown in the following inference rules:
(VAR x E∥C,S,(ΔN,ΔS))∥T⇉TT∥(E∥VAR_I x∥C,S,(ΔN,ΔS))
(VAR_I x∥C,v∥S,(ΔN,ΔS))∥T⇉TT∥(C,S,(ΔN[x←v],ΔS))
The variable name x is an address to a string object in the heap, and the expression E is an address to a instruction object in the heap. The result of evaluating the expression E will be pushed into the stash, from which the VAR_I instruction will pop the value and bind it to the variable x in the environment frame.
After declaring a variable, we can get its value using the NAME instruction and its address using the NAME_ADDRESS instruction. Both instructions will push the value or address of the variable into the stash.
This is shown in the following inference rules:
(NAME x∥C,S,(ΔN,ΔS))∥T⇉TT∥(C,ΔN(x)∥S,(ΔN,ΔS))
(NAME_ADDRESS x∥C,S,(ΔN,ΔS))∥T⇉TT∥(C,ΔN(x)a∥S,(ΔN,ΔS))
With the NAME_ADDRESS instruction, we can assign a new value (from an expression E) to an existing variable using the ASSIGN instruction. The ASSIGN instruction will push the value of the expression E into the stash, followed by the address of the variable into the stash, and then the ASSIGN_I instruction will assign the value to the variable.
This is shown in the following inference rules:
(ASSIGN x E∥C,S,(ΔN,ΔS))∥T⇉TT∥(E∥NAME_ADDRESS x∥ASSIGN_I∥C,S,(ΔN,ΔS))
((ASSIGN_I∥C,a∥v∥S,(ΔN,ΔS))∥T,H)⇉T,H(T∥(C,S,(ΔN,ΔS)),H[a←v])
Sequence and Block
A sequence of instructions is executed using the SEQUENCE instruction. The SEQUENCE instruction will execute the first instruction I in the sequence, followed by the SEQUENCE instruction with the rest of the instructions I′. In the heap, the SEQUENCE instruction is represented as a linked list of instructions.
This is shown in the following inference rules:
I=nil(SEQUENCE I I′∥C,S,E)∥T⇉TT∥(I∥SEQUENCE I′∥C,S,E)
I=nil(SEQUENCE I∥C,S,E)∥T⇉TT∥(C,S,E)
A block of instructions is executed using the BLOCK instruction. The BLOCK instruction will push a new environment frame into the environment. After the block is executed, the EXIT_SCOPE_I instruction will pop the environment frame.
This is shown in the following inference rule:
(BLOCK body∥C,S,(ΔN,ΔS))∥T⇉TT∥(body∥EXIT_SCOPE_I∥C,S,(∅∥ΔN,ΔS))
An EXIT_SCOPE_I instruction will pop the environment frame. This is shown in the following inference rule:
(EXIT_SCOPE_I∥C,S,(F∥ΔN,ΔS))∥T⇉TT∥(C,S,(ΔN,ΔS))
For Loop
A for loop statement is defined in BNF as follows:
ForStmt = "for" WhiteSpace InitStmt ";" Expression ";" UpdStmt Block
InitStmt = Assignment | VarDecl
UpdStmt = Assignment | PostfixStmt
When the FOR instruction is executed, the init part is executed first, followed by the condition part. Next, the FOR_I instruction will checks for the result of evaluting the condition and determine the next steps. As FOR_I needs to know the loop variable, it is also determined and passed to the FOR_I instruction. The FOR instruction also needs to create a new environment frame for the loop variable (if any).
This is shown in the following inference rules:
init=VAR x E(FOR init condition update body ∥C,S,(ΔN,ΔS))∥T⇉TT∥(init∥condition∥FOR_I condition update body x∥EXIT_SCOPE_I∥C,S,(∅∥ΔN,ΔS))
init=VAR x E(FOR init condition update body ∥C,S,(ΔN,ΔS))∥T⇉TT∥(init∥condition∥FOR_I condition update body nil∥EXIT_SCOPE_I∥C,S,(∅∥ΔN,ΔS))
When the FOR_I instruction is executed, it takes the topmost value in the stash as the result of the condition. If the condition is true, the body is executed, followed by the update part, the condition part, and the FOR_I instruction again. If the condition is false, the loop is exited.
If there is a loop variable, a new environment frame is created for an iteration-scope copy of the loop variable. This copy should be copied back to the loop-scope variable at the end of the iteration.
Additionally, there is a MARKER_I instruction after the body to handle CONTINUE instructions. We cannot use FOR_I as the marker since the copying of the loop variable must be done after a CONTINUE.
This is shown in the following inference rules:
I=FOR_I condition update body loopVarloopVar=nil(I ∥C,true∥S,(ΔN,ΔS))∥T⇉TT∥(body∥MARKER_I∥update∥condition∥I∥C,S,(ΔN,ΔS))
I=FOR_I condition update body loopVarloopVar=x=nil(I ∥C,true∥S,(ΔN,ΔS))∥T⇉TT∥(body∥MARKER_I∥NAME x∥EXIT_SCOPE_I∥NAME_ADDRESS x∥ASSIGN_I∥update∥condition∥I∥C,S,(∅[x←ΔN(x)]∥ΔN,ΔS))
I=FOR_I condition update body loopVar(I ∥C,false∥S,(ΔN,ΔS))∥T⇉TT∥(C,S,(ΔN,ΔS))
∅[x←ΔN(x)]∥ΔN is the environment frame ΔN with a new child frame containing a copy of the variable x. After the loop body is executed, the NAME instruction retrieves the value of the loop variable from the iteration-scope copy, the NAME_ADDRESS instruction (after EXIT_SCOPE_I) retrieves the address of the loop variable in the loop-scope frame, and the ASSIGN_I instruction assigns the value of the loop variable to the loop-scope frame.
The evaluation of a MARKER_I instruction does not produce side effects:
(MARKER_I ∥C,S,E)∥T⇉TT∥(C,S,E)
A BREAK instruction will create a BREAK_I instruction in the control stack, which pops from the control stack until it pops out the FOR_I instruction. On the other hand, a CONTINUE instruction will create a CONTINUE_I instruction in the control stack, which pops from the control stack until it pops out the MARKER_I instruction. All instructions except EXIT_SCOPE_I will be ignored during the popping process.
This is shown in the following inference rules:
(BREAK∥C,S,E)∥T⇉TT∥(BREAK_I∥C,S,E)
I=FOR_I(BREAK_I∥I∥C,S,E)∥T⇉TT∥(C,S,E)
I=EXIT_SCOPE_I(BREAK_I∥I∥C,S,(F∥ΔN,ΔS))∥T⇉TT∥(BREAK_I∥C,S,(ΔN,ΔS))
I=FOR_II=EXIT_SCOPE_I(BREAK_I∥I∥C,S,E)∥T⇉TT∥(BREAK_I∥C,S,E)
(CONTINUE∥C,S,E)∥T⇉TT∥(CONTINUE_I∥C,S,E)
I=MARKER_I(CONTINUE_I∥I∥C,S,E)∥T⇉TT∥(C,S,E)
I=EXIT_SCOPE_I(CONTINUE_I∥I∥C,S,(F∥ΔN,ΔS))∥T⇉TT∥(CONTINUE_I∥C,S,(ΔN,ΔS))
I=MARKER_II=EXIT_SCOPE_I(CONTINUE_I∥I∥C,S,E)∥T⇉TT∥(CONTINUE_I∥C,S,E)
Go Function Call
A go function call is defined in BNF as follows:
GoStmt = "go" FunctionCall
When the GO_CALL_STMT instruction is executed, it will evaluate the function and function arguments, followed by GO_CALL_I. The GO_CALL_I instruction will create a new thread with a single instruction CALL_I in the control stack, while the stash and environment are copied from the current goroutine.
This is shown in the following inference rules:
(GO_CALL_STMT CALL function args1 … argsn∥C,S,E)∥T⇉TT∥(function∥argsn∥⋯∥args1∥GO_CALL_I n∥C,S,E)
(GO_CALL_I n∥C,args1∥⋯∥argsn∥function∥S,E)∥T⇉TT∥(C,S,E)∥(CALL_I n,args1∥⋯∥argsn∥function∥S,E)
A goroutine may contain unused values in the stash and environment. However, this does not affect the correctness, and when the goroutine finishes execution, the unused values are freed due to reference counting. Note that the newly spawned thread only has the CALL_I instruction in the control stack, so it terminates after the function call is completed.
Mutex Lock and Unlock
Mutex is implemented as a struct, which contains a special heap object as its member. We define a mutex as a tuple (s,Q) where s is the state of the mutex (true if locked and false if unlocked) and Q is its wait queue (a list of threads, similar to the scheduler). We encapsulate blocked threads in Q by a special heap object called Waker(C,S,E).
We design Waker(C,S,E) to have a special behaviour:
- The first time that it wakes up a thread (C,S,E), it replaces itself with a Waker∅.
- The second time onwards, if it is requested to wake up a thread again (since it holds ∅), it does nothing.
We design Waker this way to be able to implement select, as we need to be able to wait until one of the channels is ready to send or receive; the channels involved in a select will have a reference to the same Waker object, so it only wakes up the thread the first time a channel is ready (and does nothing the second time onwards). In the inference rules below for mutex, we do not enforce Waker's behaviour as we only require this behaviour in the channel implementation.
When Lock() is called on a mutex, the mutex is locked and the thread is pushed into the scheduler if it is unlocked. Otherwise, the current thread is added to the wait queue of the mutex.
M=H(Ma)=(false,Q)((CALL_I 0∥C,sync.MutexLock (builtin)∥M∥S,E),H)∥T⇉T,H(T∥(C,S,E),H[Ma←(true,Q)])
M=H(Ma)=(true,Q)((CALL_I 0∥C,sync.MutexLock (builtin)∥M∥S,E)∥T,H)⇉T,H(T,H[Ma←(true,Q∥Waker(C,S,E))])
When Unlock() is called on a mutex, the mutex is unlocked and the first thread in the wait queue is popped and pushed into the scheduler (if any). It throws an error if the mutex is already unlocked.
M=H(Ma)=(true,WakerT∥Q)((CALL_I 0∥C,sync.MutexUnlock (builtin)∥M∥S,E)∥T,H)⇉T,H(T∥(C,S,E)∥T,H[Ma←(true,Q)])
M=H(Ma)=(true,∅)((CALL_I 0∥C,sync.MutexUnlock (builtin)∥M∥S,E)∥T,H)⇉T,H(T∥(C,S,E),H[Ma←(false,∅)])
M=H(Ma)=(false,Q)((CALL_I 0∥C,sync.MutexUnlock (builtin)∥M∥S,E)∥T,H)⇉T,Hε
where ε is the error state.
Channel Send and Receive
The implementation of channels uses the same idea as above, except that there is one waiting queue for sending and one waiting queue for receiving. Also, they use specialized instructions CHAN_SEND_I and CHAN_RECEIVE_I rather than using built-in functions.
We define a channel as a tuple (B,QS,QR) where B is the buffer of the channel, QS is the send waiting queue, and QR is the receive waiting queue. We encapsulate blocked threads in QS and QR by special heap objects called WaitingInstanceW,V,b where:
- W is a Waker(C,S,E)
- V is the value to be sent (on receive, V=nil)
- b is an instruction to be pushed into the control stack after the thread is woken up. This is mainly used for
select implementation, although we need to define it here.
We use a shorthand WaitingInstance(C,S,E),V to denote WaitingInstanceWaker(C,S,E),V,∅.
For a channel X=(B,QS,QR), we maintain the following invariants at all times:
- If QS is non-empty, then B is full (len(B)=cap(B)).
- If QR is non-empty, then B is empty (len(B)=0).
Furthermore, we enforce the special behaviour of Waker as described in the mutex section.
When Send() is called on a channel, the value is sent to a thread in QR if any, or pushed into the buffer if there is space. Otherwise, the current thread is added to the send waiting queue of the channel. This is shown in the following inference rules:
(CHAN_SEND channel value∥C,S,E)∥T⇉TT∥(value∥channel∥CHAN_SEND_I∥C,S,E)
X=H(Xa)=(B,QS,WaitingInstanceW,∅,b∥QR)len(B)=0W=H(Wa)=Waker∅((CHAN_SEND_I∥C,X∥V∥S,E)∥T,H)⇉T,H((CHAN_SEND_I∥C,X∥V∥S,E)∥T,H[Xa←(B,QS,QR)])
X=H(Xa)=(B,QS,WaitingInstanceW,∅,b∥QR)len(B)=0W=H(Wa)=Waker(CW,SW,EW)((CHAN_SEND_I∥C,X∥V∥S,E)∥T,H)⇉T,H(T∥(C,S,E)∥(b∥CW,V∥SW,EW),H[Xa←(B,QS,QR)][Wa←Waker∅])
X=H(Xa)=(B,QS,QR)len(QR)=0len(B)<cap(B)((CHAN_SEND_I∥C,X∥V∥S,E)∥T,H)⇉T,H(T∥(C,S,E),H[Xa←(B∥V,QS,QR)])
X=H(Xa)=(B,QS,QR)len(QR)=0len(B)=cap(B)((CHAN_SEND_I∥C,X∥V∥S,E)∥T,H)⇉T,H(T,H[Xa←(B,QS∥WaitingInstance(C,S,E),V,QR)])
Note that if QR is non-empty, we will keep popping the frontmost WaitingInstance as long as it holds Waker∅.
When Receive() is called on a channel, the value is popped from the buffer if there is any, and if there is a thread in QS, its value is pushed into the buffer. Otherwise, the current thread is added to the receive waiting queue of the channel. This is shown in the following inference rules:
(CHAN_RECEIVE channel∥C,S,E)∥T⇉TT∥(channel∥CHAN_RECEIVE_I∥C,S,E)
X=H(Xa)=(B,WaitingInstanceW,V′,b∥QS,QR)len(B)=cap(B)W=H(Wa)=Waker∅((CHAN_RECEIVE_I∥C,X∥S,E)∥T,H)⇉T,H((CHAN_RECEIVE_I∥C,X∥S,E)∥T,H[Xa←(B,QS,QR)])
X=H(Xa)=(V∥B,WaitingInstanceW,V′,b∥QS,QR)len(B)=cap(B)>0W=H(Wa)=Waker(CW,SW,EW)((CHAN_RECEIVE_I∥C,X∥S,E)∥T,H)⇉T,H(T∥(C,V∥S,E)∥(b∥CW,SW,EW),H[Xa←(B∥V′,QS,QR)][Wa←Waker∅])
X=H(Xa)=(B,WaitingInstanceW,V′,b∥QS,QR)len(B)=cap(B)=0W=H(Wa)=Waker(CW,SW,EW)((CHAN_RECEIVE_I∥C,X∥S,E)∥T,H)⇉T,H(T∥(C,V′∥S,E)∥(b∥CW,SW,EW),H[Xa←(B,QS,QR)][Wa←Waker∅])
X=H(Xa)=(V∥B,QS,QR)len(QS)=0((CHAN_RECEIVE_I∥C,X∥S,E)∥T,H)⇉T,H(T∥(C,V∥S,E),H[Xa←(B,QS,QR)])
X=H(Xa)=(B,QS,QR)len(QS)=0len(B)=0((CHAN_RECEIVE_I∥C,X∥S,E)∥T,H)⇉T,H(T,H[Xa←(B,QS,QR∥WaitingInstance(C,S,E),∅)])
Note that if QS is non-empty, we will keep popping the frontmost WaitingInstance as long as it holds Waker∅.
Select Statement
Go's select statement is a way to wait on multiple channel operations with several optimizations. Generally, it can be defined as follows:
- If there is at least one channel operation that can proceed without blocking, it will randomly choose one of them to execute, and continue with the
case body.
- If all channel operations would block, and a
default case is present, it will execute the default case.
- Otherwise, it will block until one of the channel operations can proceed, and then execute the corresponding
case body.
Note that in a case channel send or receive, it may have consist of complex operations. For example, the channel involved in a case may be a result of a function call or even a blocking expression (e.g., the receive of a channel of channels). Similarly, on case with a channel send, the value to be sent may be blocking. Therefore, our implementation of select will evaluate all involved channels and send values (which may block) in cases before actually doing the select.
To evaluate all involved channels and send values, we use the SELECT instruction, with the following inference rule:
(SELECT cases1 … casesn∥C,S,E)∥T⇉TT∥(f(casesn)∥⋯∥f(cases1)∥SELECT_I cases∥C,S,E)
where we define f(case) as:
case=case_send channel value bodyf(case)=value∥channel
case=case_receive channel bodyf(case)=channel
case=case_default bodyf(case)=∅
In our actual implementation, we also allow case_receive to have an ASSIGN instruction to assign the received value to a variable. However, for simplicity, we omit this in the inference rules.
When SELECT_I is executed, it will randomly choose one of the cases that can proceed without blocking, and execute the body of the case. If all cases would block, it will block until one of the cases can proceed.
Since we need to be able to add body to the top of the control stack, we need to encode it in WaitingInstance. We encode the body as the parameter b in WaitingInstanceW,V,b previously defined, where b is the body of the case (possibly b=∅).
To write all possible inference rules mathematically for n cases would take an exponential amount of space; however, algorithmically, it is straightforward to implement with multiple if statements. Therefore, for simplicity, we will only show the inference rule for the following SELECT_I instruction:
- There are two
cases with a channel send and a channel receive, respectively.
- The first
case is a channel send is on a channel X=(BX,QXS,QXR) with a value V to be sent, and it has a body bX.
- The second
case is a channel receive is on a channel Y=(BY,QYS,QYR), and it has a body bY. The return value of the receive is pushed into the stash. In the actual implementation, the first instruction of bY is either an ASSIGN instruction (to assign the received value on top of the stash to a variable) or a POP instruction (to pop the received value from the stash). We assume bY follows this convention.
- X and Y are different channels, and both channels are not unbuffered (cap(X)>0 and cap(Y)>0).
- If QXR is non-empty, then the frontmost WaitingInstance in QXR does not hold Waker∅.
- If QYS is non-empty, then the frontmost WaitingInstance in QYS does not hold Waker∅.
- If both
cases can proceed without blocking, the case with the channel send (channel X) will be executed.
If channel X can proceed without blocking, we have the two following inference rules. Note that it is very similar to the inference rules for CHAN_SEND_I.
X=H(Xa)=(BX,QXS,WaitingInstanceW,∅,b∥QXR)len(BX)=0W=H(Wa)=Waker(CW,SW,EW)((SELECT_I cases∥C,X∥V∥Y∥S,E)∥T,H)⇉T,H(T∥(bX∥C,S,E)∥(b∥CW,V∥SW,EW),H[Xa←(BX,QXS,QXR)][Wa←Waker∅])
X=H(Xa)=(BX,QXS,QXR)len(QXR)=0len(BX)<cap(BX)((SELECT_I cases∥C,X∥V∥Y∥S,E)∥T,H)⇉T,H(T∥(bX∥C,S,E),H[Xa←(BX∥V,QXS,QXR)])
If the channel X would block, and the channel Y can proceed without blocking, we have the following inference rule. Note that it is very similar to the inference rules for CHAN_RECEIVE_I.
X=H(Xa)=(BX,QXS,QXR)len(QXR)=0len(BX)=cap(BX)Y=H(Ya)=(VY∥BY,WaitingInstanceW,VY′,b∥QYS,QYR)len(BY)=cap(BY)>0W=H(Wa)=Waker(CW,SW,EW)((SELECT_I cases∥C,X∥V∥Y∥S,E)∥T,H)⇉T,H(T∥(bY∥C,VY∥S,E)∥(b∥CW,SW,EW),H[Ya←(BY∥VY′,QYS,QYR)][Wa←Waker∅])
X=H(Xa)=(BX,QXS,QXR)len(QXR)=0len(BX)=cap(BX)Y=H(Ya)=(VY∥BY,QYS,QYR)len(QYS)=0((SELECT_I cases∥C,X∥V∥Y∥S,E)∥T,H)⇉T,H(T∥(bY∥C,VY∥S,E),H[Ya←(BY,QYS,QYR)])
If both channels would block, we have the following inference rule:
X=H(Xa)=(BX,QXS,QXR)len(QXR)=0len(BX)=cap(BX)Y=H(Ya)=(BY,QYS,QYR)len(QYS)=0len(BY)=0W=H(Wa)=Waker(C,S,E)IX=WaitingInstanceW,V,bXIY=WaitingInstanceW,∅,bY((SELECT_I cases∥C,X∥V∥Y∥S,E)∥T,H)⇉T,H(T,H[Xa←(BX,QXS∥IX,QXR)][Ya←(BY,QYS,QYR∥IY)])
Project Source
Our project source code is available on GitHub at benson1029/go-slang. It is a standalone React application that can be run locally, or deployed to GitHub Pages on https://benson1029.github.io/go-slang/.
To run the project locally, you need to have Node.js and npm installed. After that, you can run the application locally by running the following commands:
git clone https://github.com/benson1029/go-slang.git
cd go-slang
npm install
npm start
Then, open http://localhost:3000 to view it in your browser.
Test Cases
Unit tests for the parser and preprocessor (specially, the module for sorting global declarations) are available in src/go/parser/go.test.js and src/go/ece/loader/globalSort.test.ts. Integration tests for the ECE machine are available under the directory src/go/ece/tests, which cover all language constructs that are supported by the ECE machine.
For most test cases that does not involve recursive calls, we additionally check whether all objects in the heap are freed after the program execution. This confirms that our reference counting garbage collector is working correctly. Recursive calls will create cyclic data structures in the heap, thus we do not check for unfreed objects in these cases.
Additionally, for all test cases, we will run it a second time, triggering mark and sweep garbage collection for every heap allocation. This is to ensure that the mark and sweep garbage collector, especially the handling of temporary roots, is working correctly. Therefore, we have high confidence that our garbage collector is working correctly.
The purpose of each test is documented in the source code.
To run the tests, you can run the following command: